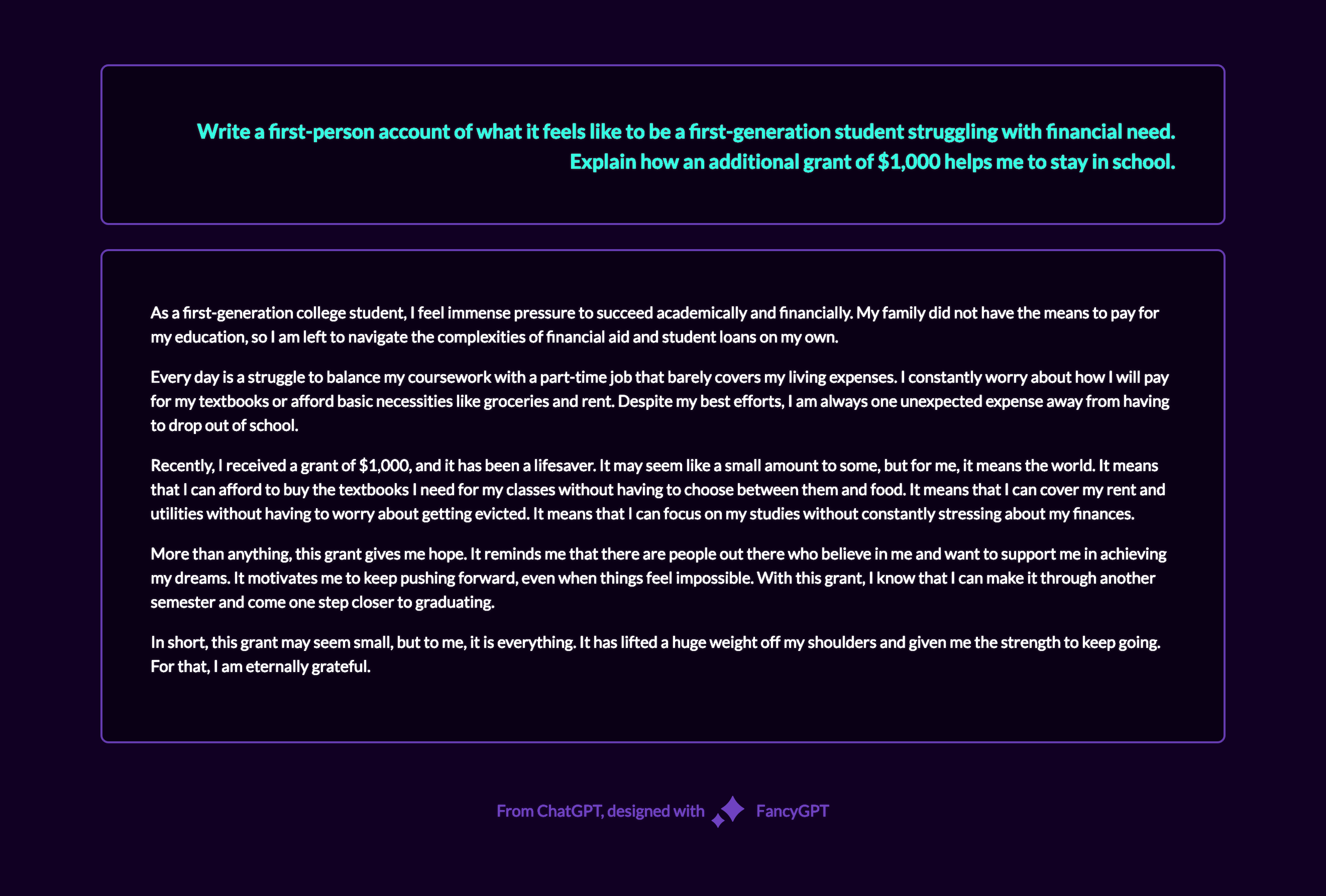
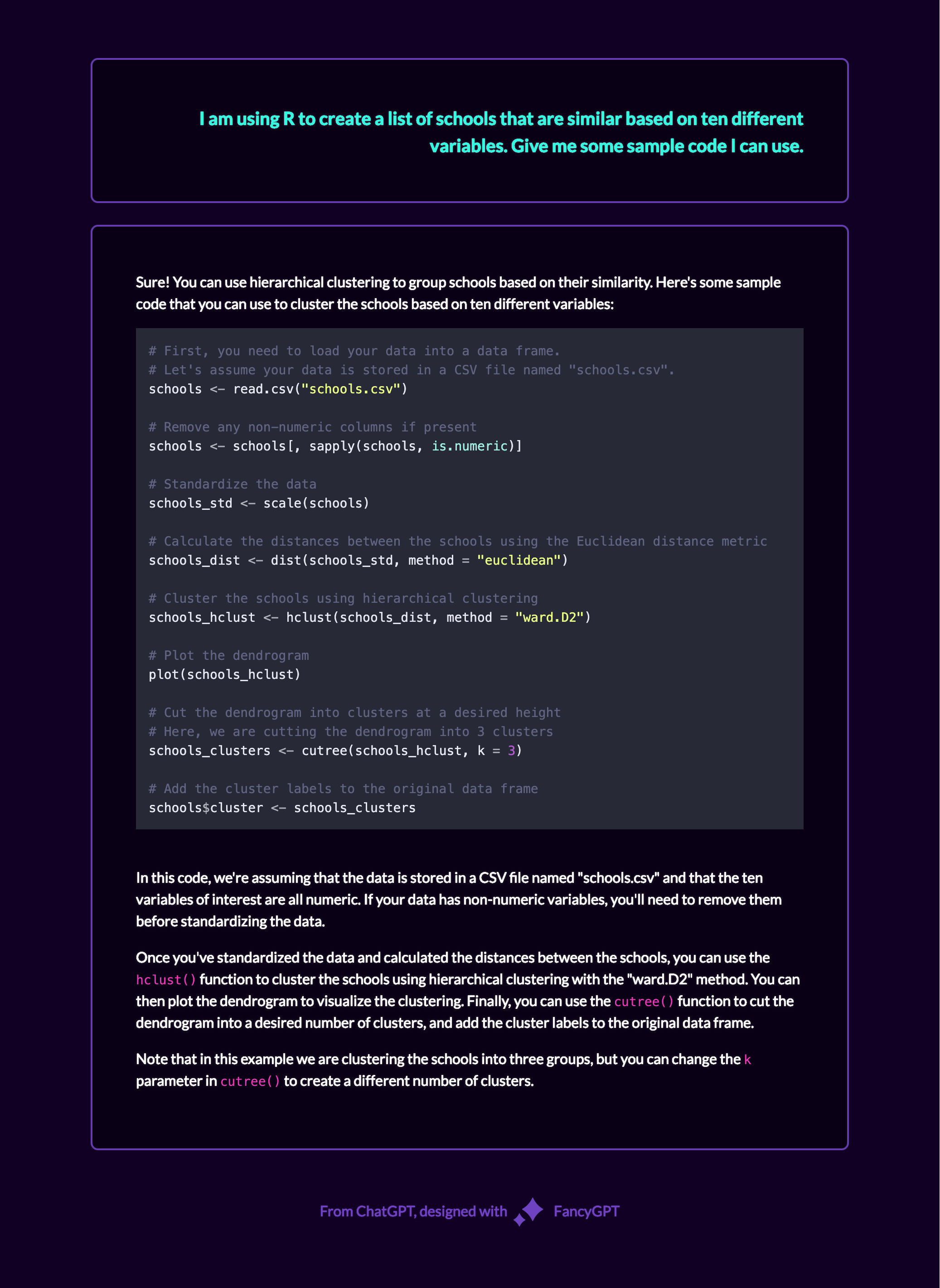
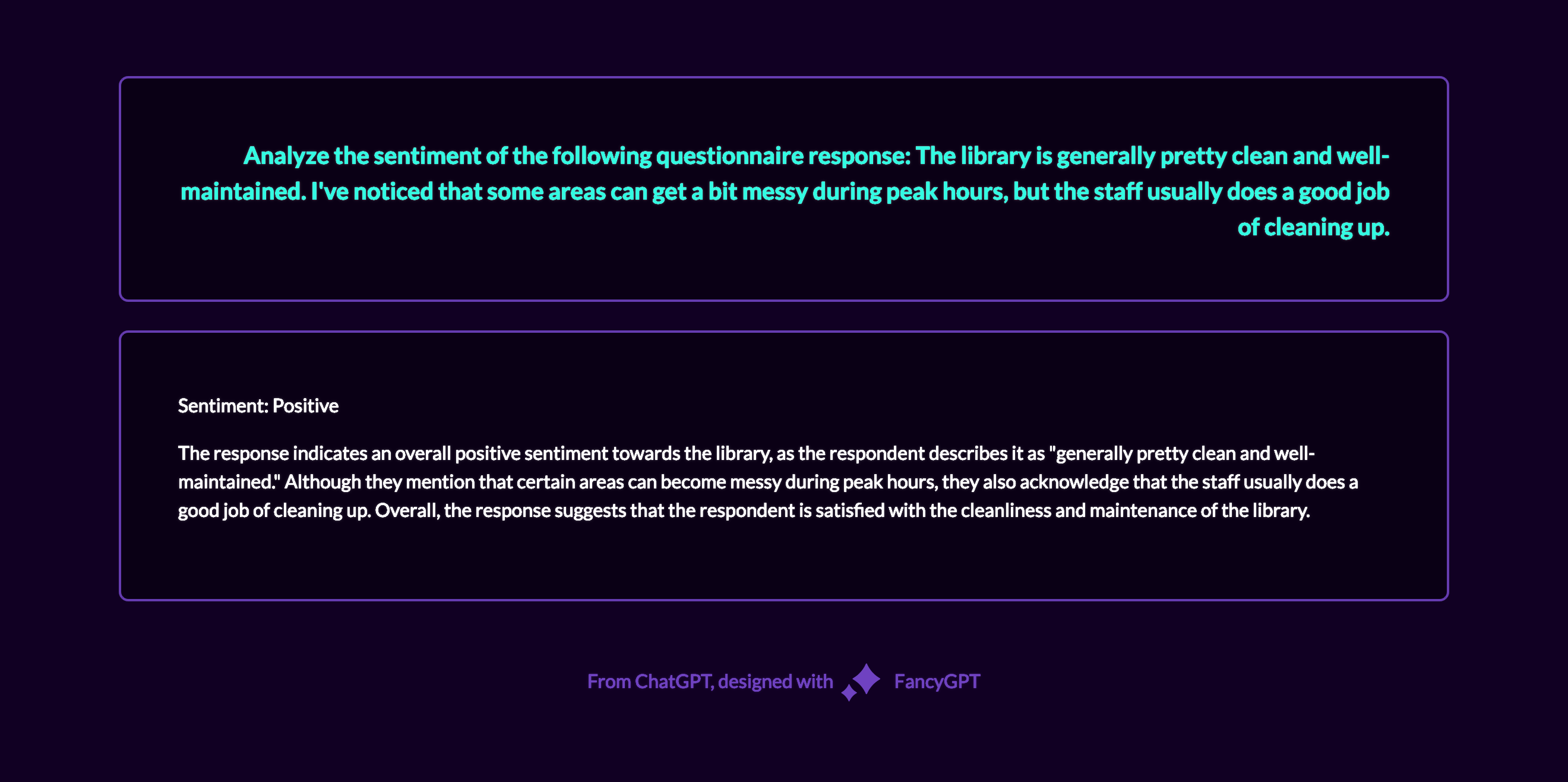
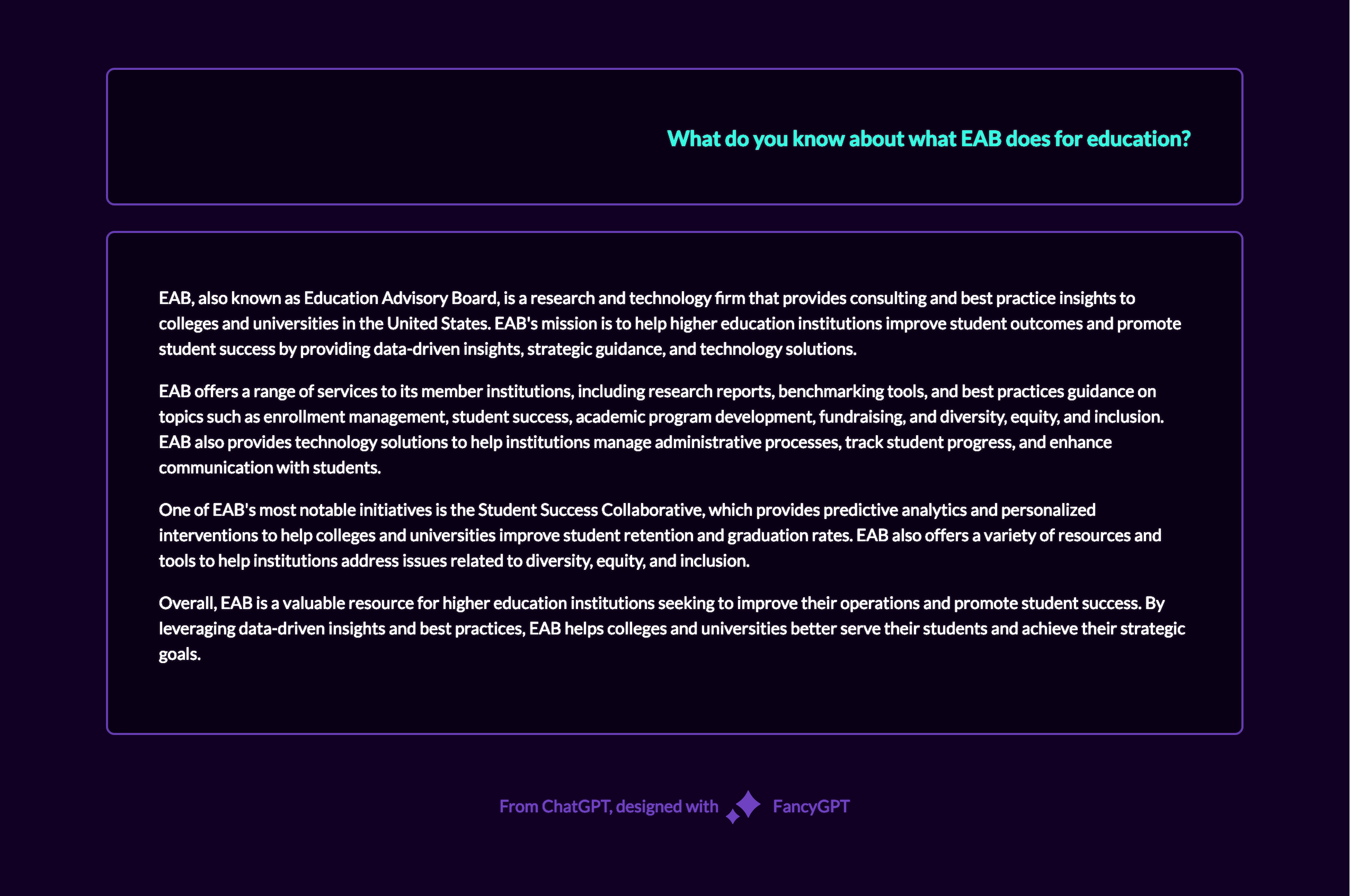
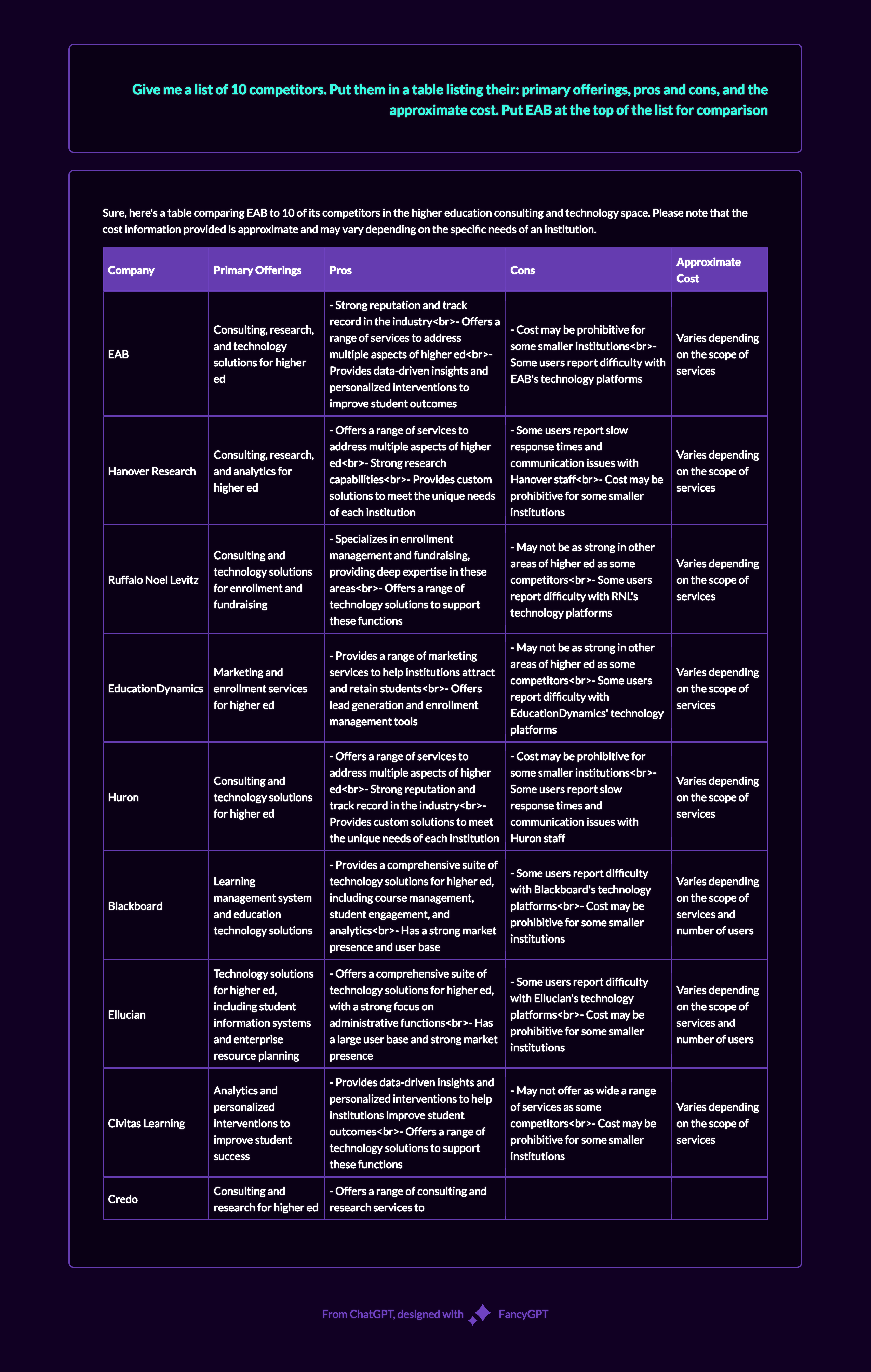
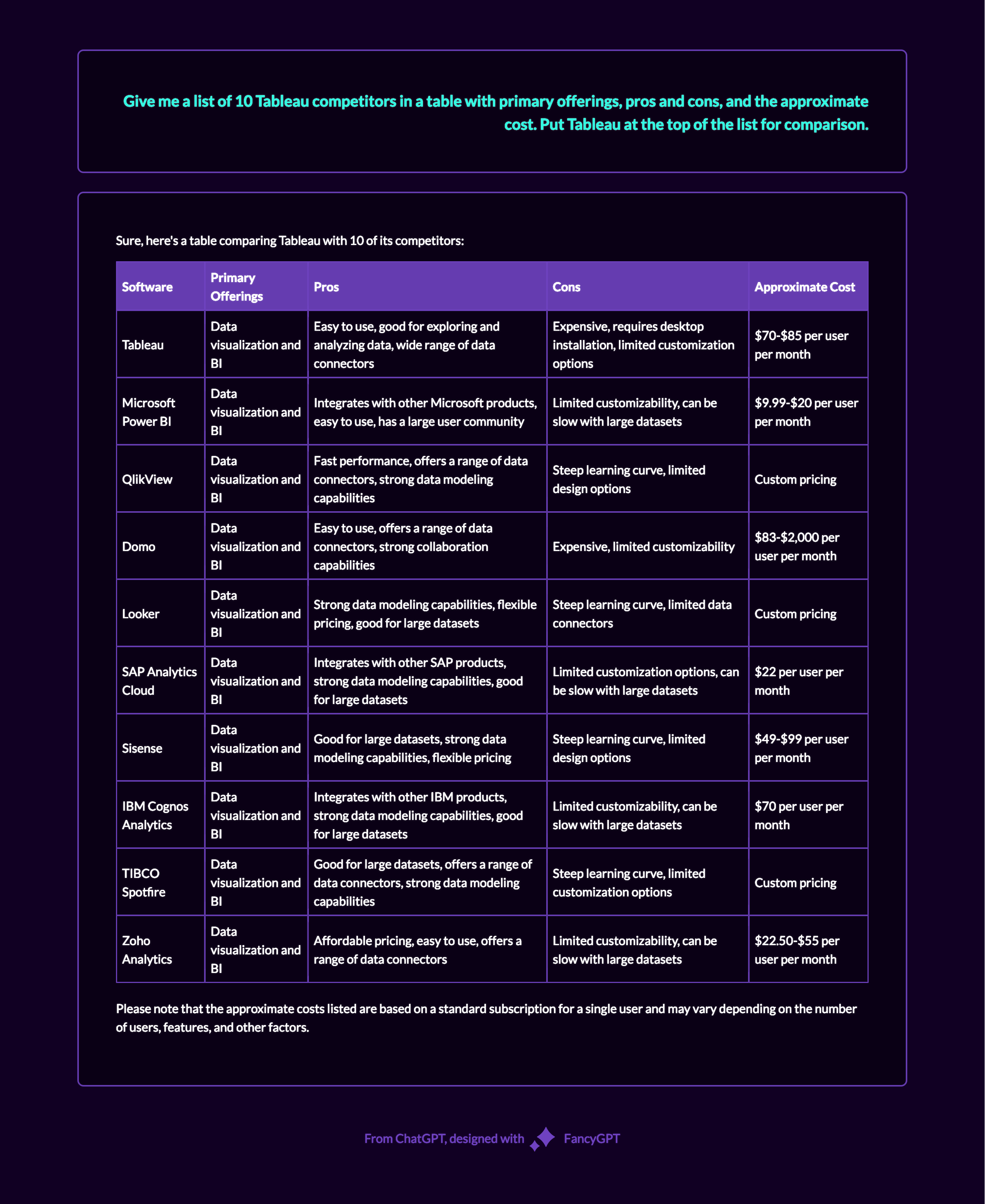
This was a fun experiment: I’m a big fan of comic books. While browsing the internet, I occasionally encounter debates over hypothetical scenarios like, ‘Who would win in a fight between Franklin Richards and Dr. Manhattan?’ Some responses are well-reasoned, while others resort to ad hominem attacks. The most insightful answers are those that examine the situation from multiple perspectives. This got me thinking about the research concept of triangulation, which aims to reduce bias by examining a question from multiple angles to offer a more nuanced understanding.
I decided to apply this approach using AI. Below are the responses to the question from GPT-4, Bard, Claude, Perplexity, and Bing, with the resulting comparison table.
Even AI tools can offer different perspectives on a question, underscoring the importance of a multi-angled approach; interestingly, Bing was the only platform that committed to a definitive answer, adding another layer to the debate.
GPT-4

Bard

Claude

Perplexity

Bing (Creative mode)

Final Result